
Advancements in AI Are Generating Believably Authentic Media
For many years, AI attempts to independently generate media fell short of human quality. While helpful for tasks like translation and summarization, this technology struggled to convincingly emulate fine details and realism.
Attempts at photo realistic image synthesis often resulted in artifacts, blurriness, or an “uncanny valley” effect where material seemed almost right but with subtle flaws.
Language models provided contextual understanding but lacked abilities to directly create visual content from text prompts alone. New approaches were clearly needed to truly transform generated media through generative AI.
The Dawn of Deep Learning through Self Supervision:
A major breakthrough came through introducing self supervised learning to domain specific models trained on gigantic image datasets. Some key developments included:
- Diffusion Models: Pioneered by Anthropic, these techniques “diffuse” input images over numerous timesteps into noise, learning the reverse process of synthesizing photos from nothing in a way that mirrors human perception.
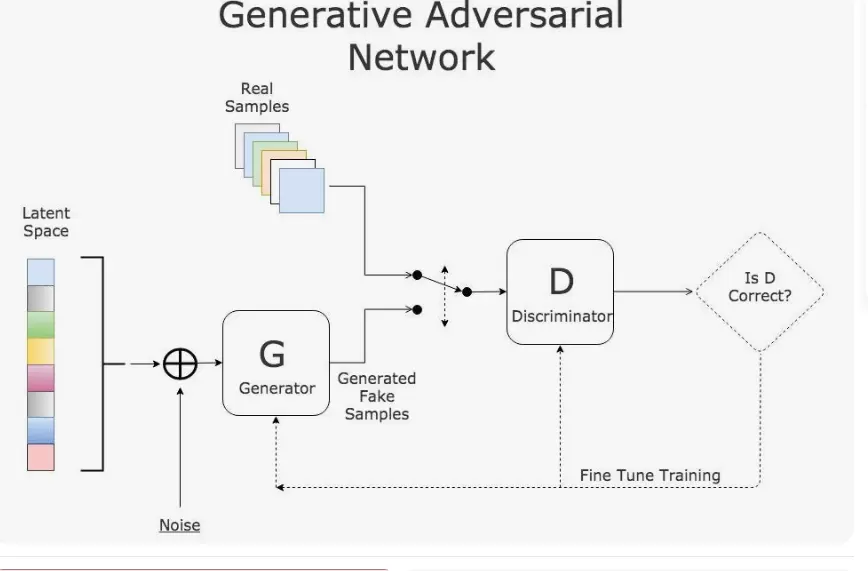
- Generative Adversarial Networks (GANs): GANs pit a generating network against a discriminating network, with both improving overtime as the generator learns to fool the discriminator into thinking its outputs are real.
- While early GANs struggled with quality, modern self supervised variants faithfully reproduce photo realistic images.
- Scale and Data: With models consuming datasets hundreds of times larger than previously feasible, they recognize and replicate finer patterns to enhance synthesis.
- Self-Supervision: Learning objectives not requiring human labels, like predicting missing image patches or sorting shuffled patches, provide a richer pre training experience than labeled data alone.
Key technical factors drove the rise of self supervised generative models, as shown in Table 1. Through parallel processing power, new architectures like Transformers, massive datasets, and self supervision techniques, models could achieve levels of visual cognition enabling dynamic content creation.
| Technical Factor | Impact on Image Generation Quality |
| Scale of Training Data | Larger datasets = more fine grained patterns learned |
| Self Supervision Techniques | Richer pre training improves generative capabilities |
| Computing Power | Increased parallelism lets scale to once unimaginable sizes |
| Model Architectures | New designs like transformer allow deeper understanding |
Authentic Media:
Transforming Image, Video and Multimedia Creation:
Equipped with innate visual perceptual abilities, generative models could now synthesize original images and compositions directly from natural language descriptions.
Popular platforms like DALL E, Midjourney, Stable Diffusion emerged, generating:
- Photorealistic persons, objects, scenes and combinations never before seen.
- High resolution digital paintings based on compute power.
- Depictions of anything describable in language, limited only by training data.
- Edited or transformed images via text signal manipulations.
- Variant outputs through iterative improvements for suitable examples.
Fine tuning for specific applications unlocked new avenues. For example, Anthropic adapted Stable Diffusion for web animation by incorporating frame by frame temporal consistencies.
While video remained challenging, DALL E 2’s text based video generation shattered limitations by producing smooth synthesized clips.
Researchers integrate pretrained language models into diffusion based video pipelines to impose intended narratives.
Scaling and Refining Multimedia Synthesis:
As techniques matured, focus shifted towards scaling and refining generative models:
Scaling Models:
- CLIP became a dominant image text model via self supervised training on public internet image text pairs, demonstrating what’s possible at immense scales.
- Models like ALIGN double CLIP’s dataset scale, training on trillions of image text examples for even deeper multi modal understanding.
Specialized Models:
- Midjourney’s Image Promoter improves stability and fidelity for product/UX imaging use cases.
- Anthropic’s PBC model trains specialized knowledge like bird identification from natural language supervision.
- AI21’s Wordridge synthesizes songs from lyrical descriptions through symbolic music generation.
User Experience Refinements:
- Iterative design makes creation simpler and more personalized through intuitive interfaces.
- Safety modes filter outputs, while creation nudges balance artistic freedom responsibly.
- Annotation tools incorporate human feedback for desirably evolving content styles.
Domain Adaptation:
- For healthcare, models generate synthetic patient data addressing privacy while training AI diagnosis.
- AI art tools help accessibility for creators with disabilities previously facing barriers.
- Educational content creation expands globally through simplified AI content authoring.
Progress in scaling and specializing multimedia synthesis aims to maximize beneficial applications helping creators across industries an around the world.
More benefits of authentic media:
Scaling Multimodal Synthesis Capabilities:
Generative AI has made tremendous strides in independently synthesizing realistic and creative content across various media formats through advances in deep learning techniques.
Early attempts struggled with fine details and realism, but self supervised learning models that harness massive datasets and computing power have achieved human level abilities. Pioneering methods like diffusion models and generative adversarial networks (GANs) now empower generative AI to convincingly depict anything describable through natural language.
Popular platforms generate photorealistic images, digital paintings, videos, and more from text alone. Continued progress specializes models for different applications, like adapting techniques for medical imaging or accessibility.
New gigantic multimodal models demonstrate deeper language-vision understanding. User experience refinements also simplify creation and iteration.
Overall, generative AI is being scaled and refined to maximize its transformative potential for beneficially facilitating media synthesis across industries worldwide.
The capabilities of these generative models have been increasingly scaled up through novel deep learning techniques and unprecedented computational resources.
FAQ
Q. Which technology helped generative AI?
A. Generative Adversarial Networks (GANs).
Q. Which technology helps generative AI create conveniently authentic media?
A. Generative Adversarial Networks (GANs)
Q. What is generative AI to create content?
A. The use of AI to create new content, like text, images, music, audio, and videos.
Q. What is generative AI MCQ?
A. A type of artificial intelligence (AI) that can create new content, such as text, images, audio, and video.
Q. What are generative technologies?
A. Generative AI models can take inputs such as text, image, audio, video, and code and generate new content into any of the modalities mentioned.
Conclusion
Technological advancements facilitating generative artificial intelligence have enabled independent content synthesis from natural language at human competitive levels across diverse media formats including images, videos and more.
Through exponential leaps in self supervised learning, models have internalized our perceptual cognition processes in ways supporting unbounded creative exploration and new opportunities for shared understanding across barriers.
While continued progress refines this technology responsibly, its transformative potential signifies an exciting future where generative AI plays an integral role facilitating believably authentic media creation benefitting all.










